Scanner, Parser, CodeGenerator
Scanner
Ein Scanner löst das sog. Wortproblem, indem er aus Lexemen Wörter zusammensetzt. Die Wörter (Befehle) einer Quelldatei werden während der lexikalischen Phase einer sog. lexikalischen Analyse unterzogen. Dazu werden die Wörter des Eingangsstroms, die als Zeichenketten (strings) angesehen werden, mittels vordefinierter „Muster“ verglichen und in sog. Token (lexikalische Einheiten, Identifikatoren) umgewandelt. Die Token sind also eine numerische Repräsentation der Strings. Diese Token entsprechen den Terminalen, die für die Grammatikprüfung im Parser notwendig sind. Diese lexikalische Analyse wird auch als Scannen bezeichnet. Dazu werden sog. reguläre Ausdrücke verwendet, die Zeichen-Muster definieren, nach denen der Scanner im Eingangsstrom sucht. Ein regulärer Ausdruck ist dadurch gekennzeichnet, dass er keine Verschachtelungen enthält. Die Untersuchung von Verschachtelungen würde Operationen auf einem Stack voraussetzen, über die ein Scanner jedoch nicht verfügt. Die lexikalische Analyse arbeitet somit rein textbasierend und wandelt Texte in Token um, wobei Token durch Integer-Konstanten dargestellt werden.
Parser
Die Syntax eines Programms wird von einem Syntax-Analysator, dem sog. Parser, untersucht. Der Parser löst dabei das sog. Satzproblem, indem er aus Wörtern Sätze zusammenfügt. Dies geschieht unter Zuhilfenahme der Grammatikregeln, die frei vom Programmierer vorgebbar sind. Die Regeln werden dazu auf den Strom von Wörtern angewendet und erzeugen dadurch gültige Sätze.
Die Aufgaben eines Parsers können wie folgt zusammengefaßt werden:
- Syntaxprüfung
- Fehlerbehandlung
- Erzeugung von Symboltabellen
- Erzeugung von Zwischencode
Die Hauptaufgabe des Parsers ist die Erzeugung von Datenstrukturen sowie die Überprüfung des Source-Codes auf syntaktische Korrektheit anhand der Grammatik. Die Grammatik erlaubt es, die Token aus der lexikalischen Phase zu analysieren und in syntaktische Einheiten zu gruppieren. Zusätzlich sollte die Position und Art des Fehlers gemeldet werden, um dem Anwender eine geeignete Korrekturmöglichkeit zu bieten. Sofern ein Compiler generiert wurde, muß der Parser die Code-Analyse nach einer Fehlererkennung fortsetzen. Dazu muß im Source-Code ein geeigneter Anknüpfpunkt gesucht werden. Zu beachten ist, dass Folgefehler möglich sind, so dass die Analyse nach einer bestimmten Anzahl von Fehlern abgebrochen wird. Falls ein Interpreter erzeugt wurde, ist der Vorgang in der Zeile der Fehlererkennung abzubrechen. Eine Grammatik, die unter Zuhilfenahme von Token angwendet wird, ist in der Regel kontextfrei, d.h. Namen, Gültigkeitsbereiche, Typen usw. werden nicht beachtet. Um diese Informationen jedoch weiterhin zu verwalten, wird eine sog. Symboltabelle (symbol table, dictionary) angelegt, in der diese Informationen und die Zuordnung zu den Token vermerkt sind. Für den Tokenstrom wird zunächst ein sog. Ableitungsbaum angelegt, der ggf. zu einem Syntaxbaum (syntax tree) komprimiert werden kann. Dieser repräsentiert entlang der Blätter und Knoten den abstrakten, kontextfreien Code. Häufig wird gleichzeitig eine semantische Analyse des Baums durchgeführt und daraus ein bewerteter (modifizierter) Syntaxbaum erzeugt. Das ist ein Syntaxbaum, der die Werte seiner Attribute in jedem Knoten zeigt. Ein Syntaxbaum ist somit eine hierarchische Darstellung der Token. Für jeden syntaktischen Block in einem Quell-Code wird dabei ein eigener Syntaxbaum angelegt. Dieser Block kann einzeilig (z.B. Wertzuweisung x=3;) oder mehrzeilig (z.B. while-Schleife), gekennzeichnet durch Klammern {}, sein.
Code-Generator
Ein Code-Generator erzeugt aus dem vereinfachten und bewerteten Syntaxbaum ausführbaren Objekt-Code, der die Regeln für die Übersetzung der Semantik des Quellcodes in einen maschinennahen Code unterstützt. Der Objekt-Code kann dabei ggf. in einer zusätzlichen Optimierungsphase vereinfacht werden, bevor der optimierte Zwischencode in einen lauffähigen Ergebniscode, etwa in Maschinensprache, umgewandelt wird. Abbildung 1 zeigt den beschriebenen Prozeß vom Source-Code zum Ergebnis-Code für ein einzeiliges Codefragment. Hierbei wird das Ergebnis in Assembler dargestellt.
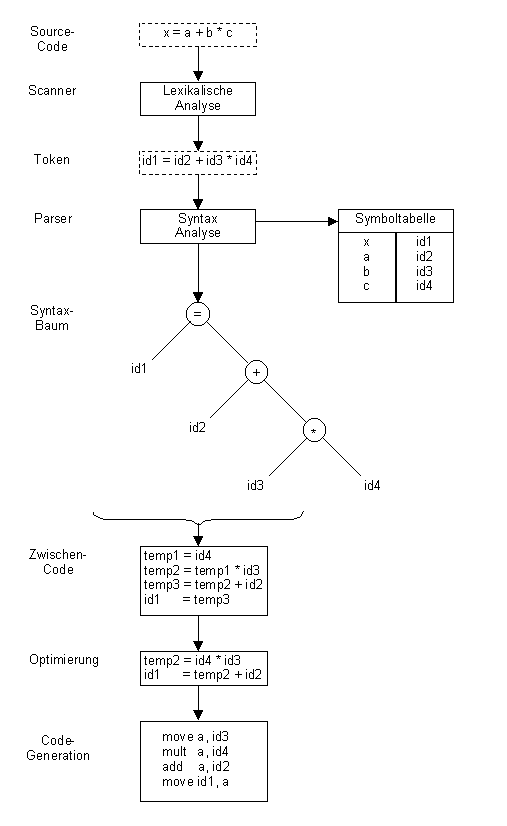
- Abbildung 1: Übersetzungsprozeß